前两天体验了一下腾讯云的在线实验,内容如题,在这里记录一下一些必要知识( 水
实验步骤
这个实验分为训练过程和测试过程两部分。
训练过程流程及实现:
- 解析脚本输入参数:使用argparse解析,由args变量持有
- 创建模型:自定义函数create_model(),返回使用keras.models.Model类创建的实例
- 模型编译:执行Model实例的compile()
- 数据增强:自定义函数create_image_generator()
- 模型训练与保存:自定义函数train()完成模型训练,使用keras.callbacks.ModelCheckpoint类的实例完成模型保存
测试过程流程及实现:
- 解析脚本输入参数:使用argparse解析,由args变量持有
- 创建模型:自定义函数create_model()
- 模型加载:使用keras.models.load_model()
- 数据读取:自定义函数create_image_generator()
- 预测与评估:自定义函数test()
环境搭建
安装TensorFlow
输入下述命令升级pip并安装TensorFlow
python -m pip install --upgrade pip && pip install tensorflow==1.14
安装Keras
输入下述命令安装Keras
pip install keras==2.3.1
安装opencv-python
输入下述命令安装opencv-python
pip install opencv-python
安装numpy
输入下述命令安装numpy
pip install numpy==1.19
编写训练代码
创建文件
进入工程目录
cd /traffic_symbol
创建train.py文件,本实验的后续代码都将在此文件中完成
touch train.py
引用文件
点击打开 train.py 文件,输入下述内容:
在文件顶部输入下述内容
import os
import argparse
import shutil
import cv2
import random
import numpy as np
import keras
from keras.applications.mobilenet import preprocess_input, MobileNet
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Model, load_model
from keras.layers import *
from keras.callbacks import ModelCheckpoint
记得保存!
保存方法:Windows 系统点击 ctrl+s,Mac OS 点击 command+s 保存
完成模型构建代码
继续在 train.py 中继续输入下面的内容,然后保存
# 创建模型
def create_model(height, width, channel, num_class):
# 加载预训练模型
base_model = MobileNet(input_shape=(height, width, channel), weights='imagenet', include_top=False)
# 把基础模型后部替换成GAP + FC
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dropout(0.5)(x)
x = Dense(256, activation='relu')(x)
predictions = Dense(num_class, activation='softmax')(x)
# 创建模型
return Model(inputs=base_model.input, outputs=predictions)
完成数据处理代码
继续添加下列代码,并保存:
# 图片增强
def preprocess(image):
# 图片格式转换为HSV
image = cv2.cvtColor(image, cv2.COLOR_RGB2HSV)
# 无关信息增强:随机改变色调、饱和度、明度
h, s, v = cv2.split(image)
shift_h = cv2.addWeighted(h, 1, h, 0, random.randint(-10, 10))
shift_hsv = cv2.merge([shift_h, s, v])
image = cv2.cvtColor(shift_hsv, cv2.COLOR_HSV2RGB)
brightness = random.randint(-50, 50)
contrast = random.uniform(0.8, 1.2)
image = cv2.addWeighted(image, contrast, image, 0, brightness)
# mobilenet的图片加速处理方式
image = preprocess_input(image)
return image
# 创建ImageDataGenerator
def create_image_generator(args, type):
classes = [str(i) for i in range(args.n_classes)]
if type == 0:
# 训练集数据处理
generator = ImageDataGenerator(
preprocessing_function=preprocess,
shear_range=0.2, # 裁剪
zoom_range=0.2, # 缩放
rotation_range=20, # 旋转
vertical_flip=False,# 纵向对称变换
horizontal_flip=True# 横向对称变换
).flow_from_directory(
args.dataset + '/train',
target_size=(model.inputs[0].shape[1], model.inputs[0].shape[2]),
batch_size=args.batch_size,
classes=classes,
class_mode='categorical'
)
elif type == 1:
# 验证集集数据处理
generator = ImageDataGenerator(
preprocessing_function=preprocess_input # 数据不做任何增强
).flow_from_directory(
args.dataset + '/validation',
target_size=(model.inputs[0].shape[1], model.inputs[0].shape[2]),
batch_size=args.batch_size,
classes=classes,
class_mode='categorical',
shuffle=False,
seed=0
)
return generator
完成训练流程代码
继续添加下列代码,并保存:
# 训练模型
def train(args, model):
# 训练数据处理
train_generator = create_image_generator(args, 0)
# 验证集数据处理
validation_generator = create_image_generator(args, 1)
# 编译模型
model.compile(optimizer=keras.optimizers.Adam(),
metrics=['accuracy'],
loss='categorical_crossentropy')
# 模型保存
model_save_path = os.path.join(args.output, 'model.h5')
saver = ModelCheckpoint(model_save_path, monitor='val_loss', verbose=1, save_best_only=True)
# 开始训练
model.fit_generator(
generator=train_generator,
epochs=args.epochs,
validation_data=validation_generator,
callbacks=[saver])
完成参数处理代码
继续添加下列代码,并保存:
if __name__ == "__main__":
# 参数解析
parser = argparse.ArgumentParser()
# 定义路径
parser.add_argument("--dataset", type=str, default="./data")
parser.add_argument("--output", type=str, default="./results")
parser.add_argument("--resume_model_path", type=str, default="")
# 定义模型参数
parser.add_argument("--n_classes", type=int, default=2)
parser.add_argument("--input_width", type=int, default=128)
parser.add_argument("--input_height", type=int, default=128)
parser.add_argument("--input_channel", type=int, default=3)
# 定义超参数
parser.add_argument("--epochs", type=int, default=5)
parser.add_argument("--batch_size", type=int, default=4)
# 过程控制。test为0表示训练,test为1表示测试
parser.add_argument("--test", type=int, default=0)
args = parser.parse_args()
print("args: ", args)
# 创建输出路径所指文件夹
os.makedirs(args.output, exist_ok=True)
# 创建模型
model = create_model(args.input_height, args.input_width, args.input_channel, args.n_classes)
# 打印模型结构
model.summary()
# 加载模型
if args.resume_model_path != "":
try:
model = load_model(args.resume_model_path)
except Exception as e:
print('No saved model, using init weights!')
if args.test:
# 预测测试图片
test(args, model)
else:
# 开始训练
train(args, model)
开始训练
使用脚本进行训练
输入下述命令执行脚本训练过程
python train.py
测试模型
输入测试数据处理函数
在 /traffic_symbol/train.py 文件中,找到 create_image_generator 方法,在 return generator 前面输入下述代码,然后保存。 请 注意缩进!
else:
# 测试集数据处理
generator = ImageDataGenerator(
preprocessing_function=preprocess_input # 数据不做任何增强
).flow_from_directory(
args.dataset + '/test',
target_size=(model.inputs[0].shape[1], model.inputs[0].shape[2]),
batch_size=args.batch_size,
classes=classes,
class_mode='categorical',
shuffle=False,
seed=0
)
输入测试流程函数
在if __name__ == "__main__":前,继续输入下面的代码,然后保存
# 模型测试
def test(args, model):
# 生成结果解析路径
result_folder = args.output + '/test'
if os.path.exists(result_folder):
shutil.rmtree(result_folder)
os.makedirs(result_folder)
# 生成测试数据集
test_generator = create_image_generator(args, 2)
# 初始化变量
total_images = 0
right_images = 0
n_val_batch = len(test_generator)
# 批量预测图片
for b in range(n_val_batch):
vx, vy = test_generator.next()
pred = model.predict(vx)
vy = np.argmax(vy, -1)
pred = np.argmax(pred, -1)
if test_generator.batch_index > 0:
idx = (test_generator.batch_index - 1) * test_generator.batch_size
else:
idx = (n_val_batch - 1) * test_generator.batch_size
files = test_generator.filepaths[idx: idx + test_generator.batch_size]
indices = [i for i, v in enumerate(pred) if pred[i] != vy[i]]
total_images += len(files)
right_images += len(files) - len(indices)
for i in range(len(files)):
img = cv2.imread(files[i], cv2.IMREAD_UNCHANGED)
text = "label" + str(vy[i]) + "_pred" + str(pred[i]) + "_"
save_path = os.path.join(result_folder, text + os.path.basename(files[i]))
cv2.imwrite(save_path, img)
print('accuracy', right_images / total_images)
模型测试
使用脚本进行测试
输入下述命令
python train.py --test 1 --resume_model_path /traffic_symbol/results/model.h5
等待测试完成,可以看到类似这样的输出
Found 16 images belonging to 2 classes.
accuracy 1.0
查看测试图片数据结果
ls /traffic_symbol/results/test
运行上述命令,可以看到输出图片的类似效果
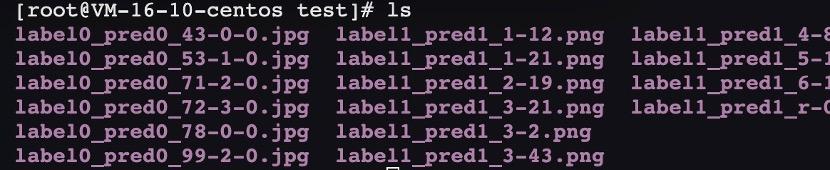
可以在这里看到所有图片的标注和预测结果。 如label0_pred0_43-0-0.jpg,意味着标注类别是0,预测结果0,原图名称是43-0-0.jpg
打开 results/test 文件夹,在 右侧目录树 点击查看测试输出图片效果